Service Mesh is not a new topic anymore. Most of us in the industry are already familiar with it. There are also tons of article in the internet about its why and how. In my opinion, it has a significant influence on the application architecture. Here's a DevSecOps humor to start the discussion (and it will make sense as you read along).

Part 2: Understanding The Ingress and The Mesh components of Service Mesh.
Part 3: Understanding the observability component of Service Mesh (TBD).
Some common questions and my short answers:
Q: Does micro-services architecture inherently warrants for service mesh?
A: No.
Q: Is it a networking tool? Is it a security tool?
A: Yes and No. In my opinion, it has application service discovery, application resiliency, connectivity and observability at the very least. Thus, networking, security are parts of it, but not all of it.
Q: If the application architecture is API driven does still need service mesh?
A: May be. Unnecessarily exposing API endpoints just so an internal service can access it is, in fact, an anti-pattern. Service Mesh can help here to standardise and simplify a great deal. To me, it absolutely makes sense to have a combination of API gateway and service mesh for the application architecture. I described this topic in this post.
Q: Does service mesh warrant for change in application source code to allow for side cars?
A: It should not. I touched on it briefly in this post but it deserves its own technical post.
Q: I need security for my application. Can service mesh provide that?
A: Yes. However, similar degree of application security can be achieved without service mesh too. In my opinion, consideration need to be made to adopt service mesh beyond just security context. Read along the rest of post to understand this better.
Feature #1 - mTLS:
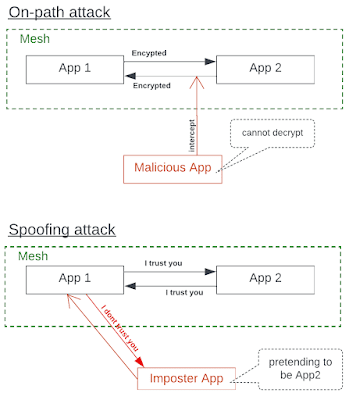
- If the workloads of the application are deployed in a secured K8s cluster with appropriate security policies, such as registry policy, image signing, RBAC etc and the deployment is only allowed through secured supply chain or approved CD process then that will prevent malicious or imposter app from getting deployed in the first place. mTLS of a Service Mesh has very little contribution in this context.
- If a bad actor gets access to a cluster and the cluster does not have appropriate security policies then it is pretty easy to deploy the malicious/imposter app inside the mesh. In which case, the mTLS will not be able to prevent the attacks.
- If the workloads of the app are deployed within a single cluster with appropriate security policies and secured supply chain then there's very little use for mTLS.
- The micro-services of the app are spread across multiple cluster. In most cases it will be.
- Workloads are only deployed via approved supply chain during the CI/CD process. This can be restricted using appropriate RBAC.
- K8s cluster must have appropriate security policies. 3 of the minimum requirements of such policies are registry policy, signed image policy and RBAC.

Feature #2 - Service discovery:

Importance score: 5
- There are additional overhead for service to service communication without service mesh using K8s default DNS, which follows this pattern: {svc_name}.{namespace}.svc.cluster.local or API gateway. It is impractical to map micro-services using the default DNS pattern as they will be developed and deployed by different teams at different times across different namespaces and often spread across different clusters. If all the micro-services are deployed in the same namespace then it works as they can be called by names. But no body does that. In short, it is not practical and cannot be managed or scaled.
On the contrary, when using Service Mesh this becomes easy to roll out and highly scalable. This is because, Service Mesh exposes services in a the mesh and enables communication among services by service names (the control plane takes care of this out-of-the-box). - I have seen API Gateway being used for exposing services (although, it was not its original intention but mutated over time and had gone out of control). In my opinion, unnecessarily creating API endpoints for discoverability or connectivity or security among internal services is an anti-pattern and scope creep to list of APIs. This can scale but slows down the process of delivery, over time leading to huge number of unused APIs. Managing and maintaining the unnecessary APIs (eg: version control, API definition, documentation etc) becomes overheads. A combination of Service Mesh and API Gateways can (and will) standardise and simplify the application and infra architecture significantly from both development and operation perspective and reduce complexity and overhead by a lot.
- In most implementations, micro-services are usually spread across multiple K8s. This is so that we can achieve things like workloads isolation and workloads grouped by service category (eg: cache service, queue processing service etc may be in a cluster different to inventory process, order management etc) or service placed in clusters for compliance reasons (eg: the payment processing service needs to remain on prem for compliance) etc. For these scenarios, a cross cluster service mesh adds simplicity to the app and infra architecture. Without service mesh there will be additional overhead and complexity (and possibly unnecessary, in my opinion) of exposing services or endpoints through API Gateway or worst through LBs and Ingress (even if they may be internal by nature).
- In multi-cluster (and multi-cloud) scenario Service Mesh provides security by default, leveraging its mTLS functionality that enables communications among micro-services using mTLS over network. This requires no change to the application architecture or source code and is handled by by sidecars or proxies. Without it, maintaining TLS for app security becomes super complex and non-scalable.
Feature #3 - Meshing:
- Peer Authentication: Using peer authentication we can apply mTLS within a mesh in appropriately. This allows fine grain controls over how workloads outside the mesh talks to workloads inside the mesh without compromising the mesh integrity or burdening application lifecycle. See below diagram:
- Circuit Breaker: Circuit breaking is an important consideration when planning a micro-service architecture for an application. It provides the below advantages:

- Limits the impact of cascading failure by immediately failing the faulty service in the mesh,
- Limits the impact of latency spikes.
- This increases the overall up time of an application and protects its underlying infrastructure from exhaustions.
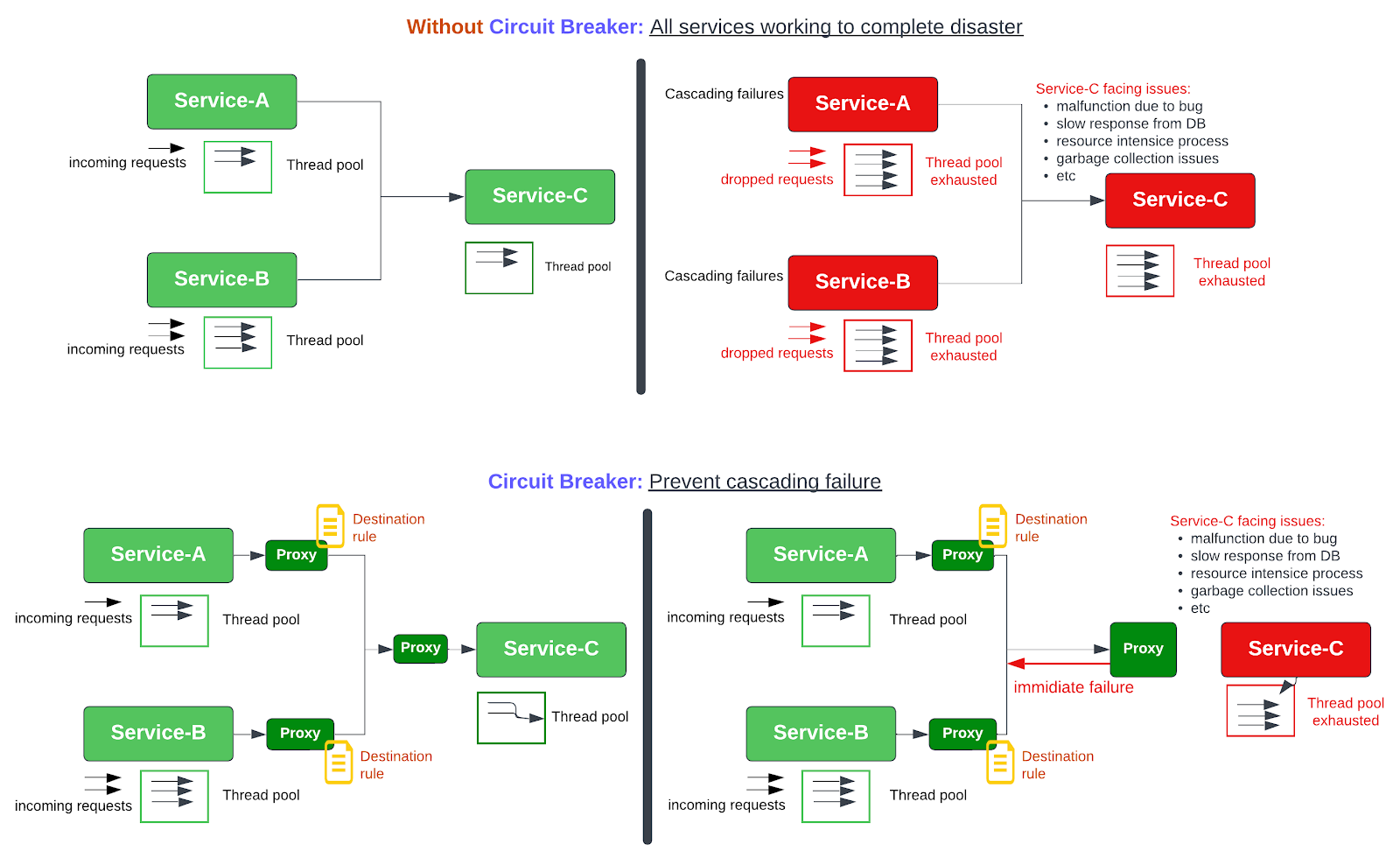
- Dev and Ops segregation. eg: No source code change needed to implement security restriction as well as application resiliency.
- Fine grained control of mTLS mode (eg global by applying to istio-system ns, overridden by at namespace level, overridden by applying with workload selector) provides flexibility to apply security context to a mesh fitting almost 95% of the usecase.
- App resiliency feature (such as circuit breaker) available out-of-box (without having to need to change in source code).
Feature #4 - Ingress, Gateway, VS etc:
.png)
- Keep the load off of the ingress controller or gateway from processing TSL and shift that responsibility to the dedicated LB itself. --> This allows me to use AWS managed certs (and minimise certificate cost) and free my K8s from managing certs for user request.
Attach AWS WAF rule to the AWS ALB --> This is the primary reason for offloading TLS at the LB.
- I can achieve AB testing using Contour Ingress. So, I do not need to choose Service Mesh for it.
- I can achieve traffic distribution using Contour Ingress. So, I do not need Istio Gateway.
- I can achieve TLS offload with Contour Ingress. So, I do not need Istio Gateway.
- And many more...
Feature #5 - Telemetries:

In this screen shot I can see:
- the p99 telemetry
- the failure percentage
- graph of the Service Mesh (eg: user request originating from ingress and the services involved to respond to the request).
- there are many other telemetry data I can get as well which are not shown in the screen shot here (that would be another post for another day).
- This feature is completely loose coupled, in terms of value add, from an app architecture perspective. In my opinion, this by itself should not warrant for service mesh adoption. We can get similar level (if not more) from specialised observability tools like Tanzu Intelligence, New relic etc. But, I must admit that it is an important good to have feature from an application's (and its micro-services) lifecycle perspective.
Feature #6 - Enterprise products and offerings:
- Global Namespace: This is, in my opinion, the critical component for choosing Service Mesh for applications. It extends the service mesh capability (discovery, connectivity, security and observability) across multiple clusters (and clouds [public and private]). I described the importance of it in feature 1 and 2.
- Global control plane: It provides a unified management interface for Istio deployments across multiple clusters, allowing operators to manage their Istio environment in a centralized manner.
- Application SLO: It allow to apply SLO rule to a mesh which performs autoscale (out and down) on services based on predictable application response times. This allows to maintain the required uptime for services and improves app resiliency.
- API security and visibility: This is is achieved through API vulnerability detection and mitigation, API baselining, and API drift detection (including API parameters and schema validation). API security is monitored using API discovery, security posture dashboards, and rich event auditing.
- PII segmentation and detection: PII data is segmented using attribute-based access control (ABAC) and is detected via proper PII data detection and tracking, and end-user detection mechanisms.

Implementing Service Mesh using Tanzu Service Mesh:

Here's how I implemented the above:
- The 3 micro-services in the diagram are part of a larger application (I am using only 3 here for brevity). The functionality these 3 micro-services provide is: it displays/accepts account information only if the username is verified based on few different conditions. 2 micro-services (frontend and account service) are written in such a way so that they take the services names from environment variables (eg: http://account/get)
- I am using SaaS org of Tanzu Mission Control (aka TMC) and Tanzu Service Mesh (aka TSM). My TMC platform is also integrated with my TSM platform.
- I created 2 EKS clusters using TMC. Then from TMC console I rolled out Istio service mesh through TSM. Here, TSM manages Istio and maintains cross cluster mesh capability. It deployed AWS NLB per cluster (total 2) for meshing purposes. For service to service communication across cluster it uses the NLB to do TLS passthrough for mTLS connection between services across cluster. TSM does not handle or keep any data communicated among services (across clusters); it simply keeps tracks of (and stores) K8s and associated LB addresses.
- I deployed the micro-services as usual with an additional annotation at the deployment definition for service mesh called sidecar.istio.io/inject: 'true'. This prompted Istio to inject sidecars in the deployed pods. The frontend micro-service also needed to accept user request, so I deployed Gateway and Virtual Service for the frontend micro-service only. The account and verification mircro-services do not require user request ingress from outside (they only accepts request from other micro-services), so they only have service definition. In reality, I did not write the yaml file by hand or deployed it manually rather it was auto generated and auto deployed by Tanzu Application Platform as part of my CI and CD process, which deserved its own post.
- When TSM deploys Istio its default behavior is to use NLB. But I wanted to using AWS ALB for ingress (for reason specified in the Feature #4 section). For this I needed to deploy another Kind: Service of Type: NodePort in the istio-system namespace and point AWS ALB to it (eg: associated target group the exposed ports).
- I applied security policies through TSM console to my mesh in order to achieve zero trust architecture. These are the enterprise features of TSM. Below are some important ones:
- PeerAuthentication globally and at pod level.
- Global Namespace level service group isolation. This is all about implementing with services are allowed to communicate enforcing workload isolation in a micro-service landscape.
- Several threat detection policies such as protocol attacks, injection, session fixation, few data leakage etc.

Conclusion:
- Not every application designed as micro-services. Now, I feel, there might be a chicken and egg situation for the applications that are already decoupled from monolith and have adopted API Gateway pattern and weirdly morphed into masking service mesh usecases. For the rest, they might not be "big" enough for service mesh.
- For every new technology adoption it inherently incurs cost of ownership (OpEx + CapEx + ChangeEx). Although service mesh is a great piece of technology it is no different to this rule. Hence, the land scape of application or applications needs to be "big" enough for service mesh cost justification.
- The human element is also another critical piece. For Developers service mesh is probably going to be a good thing and win since they won't need to write the weird logic in the source code for service security and connectivity. However, for SRE or OPS it may be a love and hate scenario as they will have the deal with things like what happens when sidecars starts to play up, what if the global meshing components for cross clusters mesh starts to not get deployed (which it probably will in some context in a 5 year run way) etc. Sure, the vendor (commercial products) will offer supports but the first line of defense are the SRE or Platform OPS. So if they are not up for it then service mesh will be another chaos to the mix.
- Most FOSS (such as Istio, LinkerD etc) service mesh provide only in cluster mesh capability. Which, in my opinion, does not add that much value for "big" applications. The value of service mesh is truly realised when used the commercial offerings (such as VMware's Tanzu Service Mesh) which magnifies the OSS mesh's (eg: Istio) capability across multiple clusters (and multiple clouds) through global control plane and augments it with advanced policy management features through a central console / control plane. So, I would only choose service mesh for my app portfolio if I have budget to buy the commercial offering of my favorite service mesh (eg: Istio).
- Before adopting it as the shiny new toy one must weigh in the cost of ownership and its architectural benefits in the context of the existing and near future app portfolio. I do not feel that looking at it from a single lense like security tooling or network tooling or observability tooling is the right way to evaluate it. Hence, I scored its features, at least the ones that I think are important, from app architecture perspective. And thus the obvious fact is, if the benefits outweighs the cost then bob is your uncle. But please, keep it is simple, don't overbake the bake off.